

近日,中國科學院深圳先進技術研究院環繞智能與多模態研究室提出從語音到舌超聲生成的統一擴散模型框架,能夠根據輸入的未知語音信號(例如健康或病理性語音),自適應地生成高保真度的舌體超聲數據,這項研究為解決言語障礙評估與康復中的相關技術難題提供了新路徑,相關研究已正式發表于國際期刊Information Fusion。
從“聽聲音”到“看舌動”的智能跨越
在言語治療與康復領域,準確、直觀觀察發音時舌頭的內部運動對于診斷評估與康復訓練具有關鍵意義。然而,傳統超聲舌成像設備因操作專業要求高、成本昂貴,在臨床普及上面臨較多限制。聲學-發音反轉(Acoustic-to-articulatory inversion,AAI)作為語音處理的重要方向,致力于從語音信號中推斷發音器官的運動姿態,構建聲音與形體之間的“翻譯橋梁”。該技術能夠將易于獲取的語音信號,轉化為難以直接觀測的發音生理數據,為言語康復、語言教學乃至無聲語音接口的開發提供新路徑。因此,基于AAI技術實現的語音到舌超聲生成方法,通過算法僅憑語音信號即可“推算”出對應的舌體運動數據,為臨床提供了一種低成本、非侵入式的可視化解決方案。
統一框架破解兩大臨床技術難題
該技術長期面臨兩大挑戰:一是配對的病理性語音-舌動數據極其稀缺,導致模型泛化性能差;二是健康與病理性言語在發音機制和聲學特性上存在顯著差異,導致模型在處理未知類型的語音時容易失敗。
面對這些挑戰,研究團隊提出了 Uni-UTIDiff統一框架。該框架的核心優勢在于:
統一建模:首次使用統一模型同時處理健康與病理性語音,無需為不同人群分別訓練專家模型,極大提升了數據利用效率和模型通用性。
智能辨音:基于對比聚類的無監督發音模式提取器,能自動判別輸入語音是正常還是異常,無需人工標注,進一步挖掘更多隱藏特征表示。
自適應生成:自適應條件融合模塊能動態地將語音特征與識別出的發音模式相結合,確保生成的舌動圖像既符合語音內容,又保留了特定發音模式(如病理性異常)的細節。
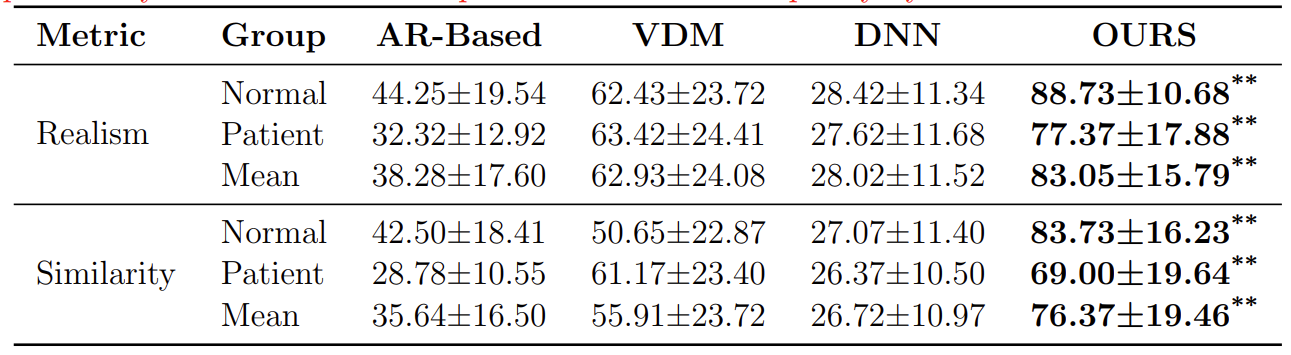
實驗結果表明,Uni-UTIDiff 不僅在統一框架下能夠分別達到針對健康與病理語音的專家模型性能水平,還能在生成的舌超聲圖像中展現出優異的清晰度與自然度,充分驗證了其在跨發音模式下的魯棒生成能力。
新一代言語智能康復與遠程醫療的應用前景
這項技術意味著,未來我們有可能僅通過一個APP收錄的用戶語音,即可生成其對應的發音器官內部運動,為下述不同場景帶來應用變化:
精準康復與遠程醫療平臺:為不同地區的構音障礙患者提供專業言語治療服務。患者通過實時可視化的舌位運動生物反饋,幫助其更有效地進行家庭專業康復訓練。
臨床輔助診斷:作為篩查工具輔助醫生快速評估患者的言語運動功能,生成客觀的影像報告,提升診斷效率。
語言教學與保護:可用于語言教學,幫助學習者直觀理解發音要領;記錄或推斷特定罕見語言的發音生理特征。
中國科學院深圳先進技術研究院王嵐、燕楠研究員為共同通訊作者,研究助理楊毓棟和高級工程師蘇榮鋒為共同第一作者。此外,中山大學第八附屬醫院招少楓主任、香港大學Manwa.L.Ng教授為論文的共同作者。該研究獲得國家重點研發計劃、國家自然科學基金、深圳市自然基金重點項目等項目支持。

文章上線截圖,論文鏈接:https://doi.org/10.1016/j.inffus.2025.103896
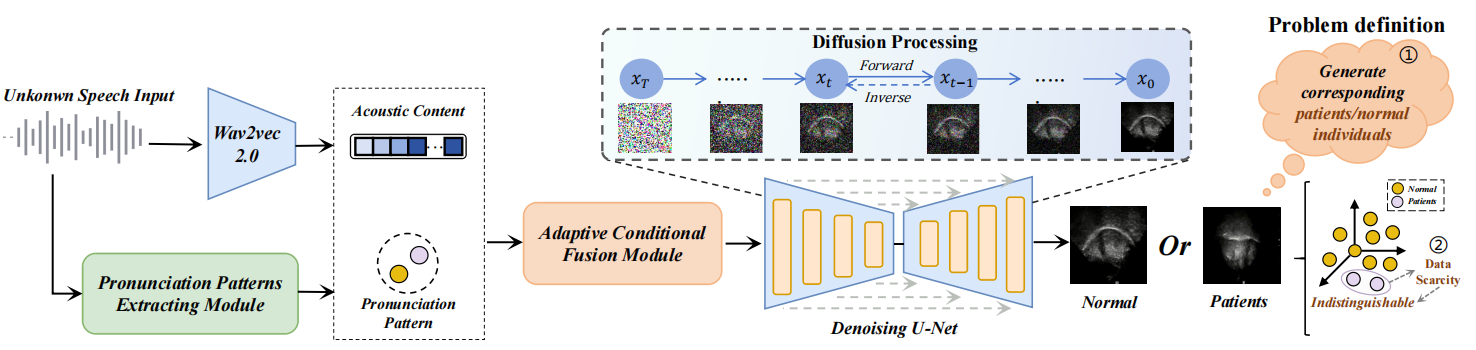
圖1?整體方法流程圖
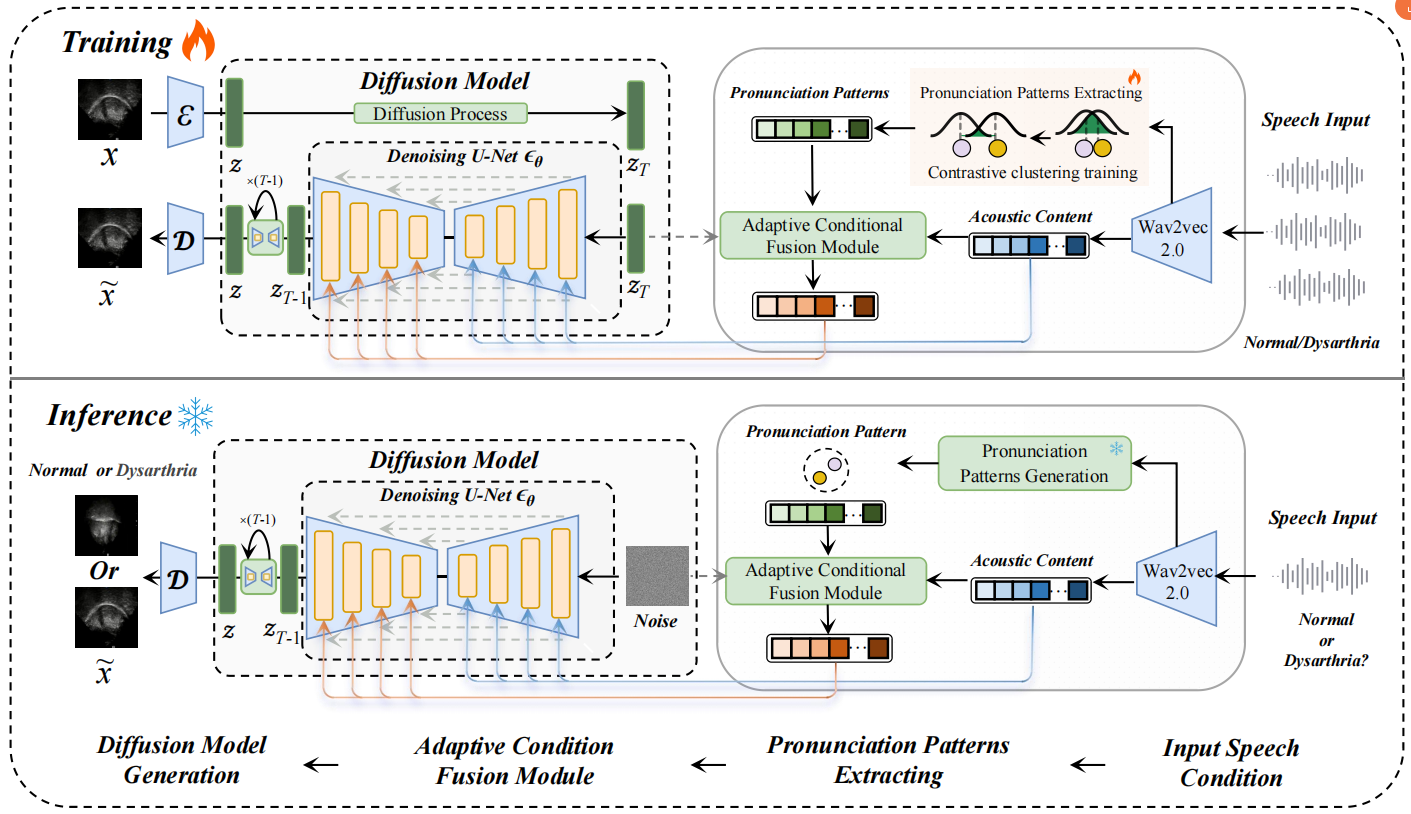
圖2 Uni-UTIDiff的訓練和推理細節
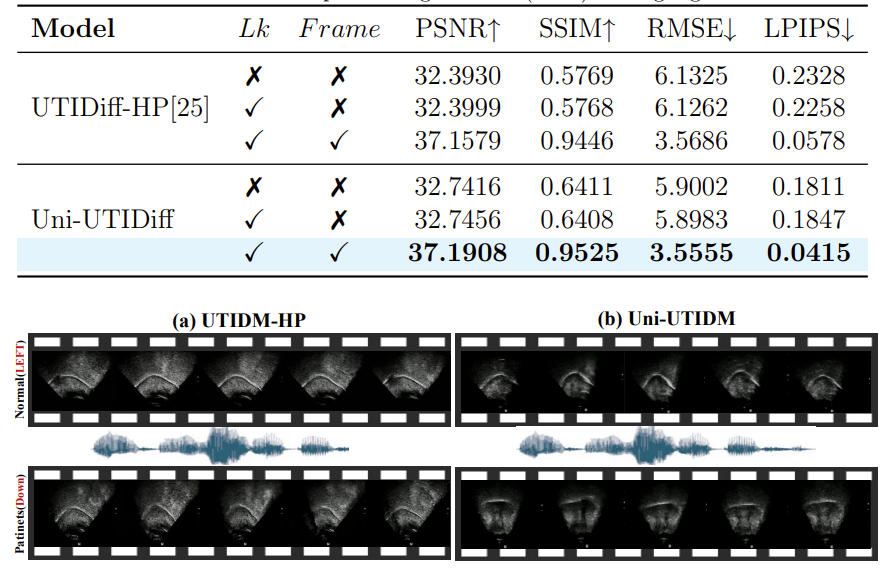
圖3?模型生成效果圖(自適應區分健康和異常患者)
附件下載: